

・img2imgの機能を使いたい
・生成したい画像の雰囲気を簡単に伝えたい
という方に向けた記事になります。
Stable Diffusionは画像生成AIのひとつで、ユーザが入力したテキスト(=プロンプト)をもとにAIが画像を生成するツールです。
しかし、テキストプロンプトのみで生成したい画像のイメージを伝えるのは難しい…という場合があります。
そこで本記事では、「Stable Diffusion img2imgの使い方」について詳しく解説します。
img2imgとは、既存の画像を元に新たな画像を生成する機能です。
img2img機能を利用することで、生成したい画像のイメージを伝えやすくなります。
※リンクをクリックすると解説場所まで飛べます。

Stable Diffusionのimg2imgとは?

Stable Diffusionのimg2imgとは、既存の画像を元に新たな画像を生成する機能です。元の構図や色合いを活かしながら、まったく違う画風やテイストに変換できる点が特徴といえます。
画像から画像を生成するため、イラストや写真を使って独自性の高い作品を作りたい方に適しています。
テキスト入力のみで画像を生成する「txt2img」と異なり、ベースとなる画像があることで出力結果の方向性をある程度コントロールしやすいのが利点です。
img2img機能でできること
img2img機能では、既存の写真やイラストを入力することで全体のレイアウトを保ちながら、画風や質感を自由に変換できます。
たとえば線画をリアル調に仕上げたり、風景写真をアニメ風や水彩画風に加工するなど、多彩な演出が可能です。
加えて部分的な修正や拡張にも対応できるため、Photoshopのような画像編集ソフトと組み合わせれば表現の幅を大きく広げられます。
ベースとなる画像の雰囲気や構造を活かしつつ、別のスタイルやアレンジを加えらた新しい画像を生成できます!
txt2imgとの違い
Stable Diffusionにはテキスト入力だけで画像を生成するtxt2img機能もありますが、img2imgとの大きな違いは「元となるビジュアルの有無」です。
txt2imgではプロンプトを頼りにゼロから画像を生成しますが、img2imgは既存の画像に基づいて新たなビジュアルを作ります。
つまり、ある程度意図した構図や形状を維持したまま別の画風に変換できる点がメリットといえます。ただし、元の画像が持つ情報が強く反映されるため、大幅な改変にはパラメータの調整が必要です。
- txt2img:テキスト(プロンプト)からまったく新しい画像を生成
- img2img:元となる画像を読み込み、テキストの指示やパラメータを加味しながら変形・再生成
WebUIでimg2imgを始めるための準備
Stable DiffusionのWebUIを利用すると、ブラウザ上でGUIを通じてimg2img機能を扱えるので視覚的に分かりやすく、初心者に適しています。
まずGPUを搭載したPC環境を用意し、WebUIのリポジトリをダウンロードしましょう。導入手順は以下の記事を参考にしてみてください!
次にモデルファイルを取得し、WebUIを起動したら「img2img」のタブから画像を読み込むだけで機能を利用できます。モデルの取得手順は以下の記事を参考にしてみてください!

Stable Diffusion WebUIのimg2imgの使い方

Stable Diffusion WebUIでimg2imgを利用する手順は以下の通りです。
- 元になる画像を準備する
- img2imgタブで画像を読み込む
- 生成サイズや解像度を指定する
- プロンプトを入力して画像を生成する
一つずつ見ていきます。
手順1:元になる画像を準備する
まずは、img2imgのベースとして利用する画像を選びます。
イラスト、写真、線画などを用意しますが、変換後のイメージをイメージしやすいように構図や主題がはっきりした素材がおすすめです。
画像の解像度が極端に低い場合は、生成結果がぼやけることがあるため、ある程度の大きさを確保しておくと良いでしょう。
ネット上にある画像、自分のPCや携帯にある画像、Stable Diffusionで出力した画像のいずれでもかまいません。画像使用時、著作権には注意してください。
今回はStable Diffusionで出力した以下の画像を元画像として新たな画像を生成していきます。

手順2:img2imgタブで画像を読み込む
続いて、準備した画像をWebUIで読み込みます。
Stable Diffusion WebUIを起動後、「img2img」タブを選択し、画像をドラッグアンドドロップまたはアップロードします。
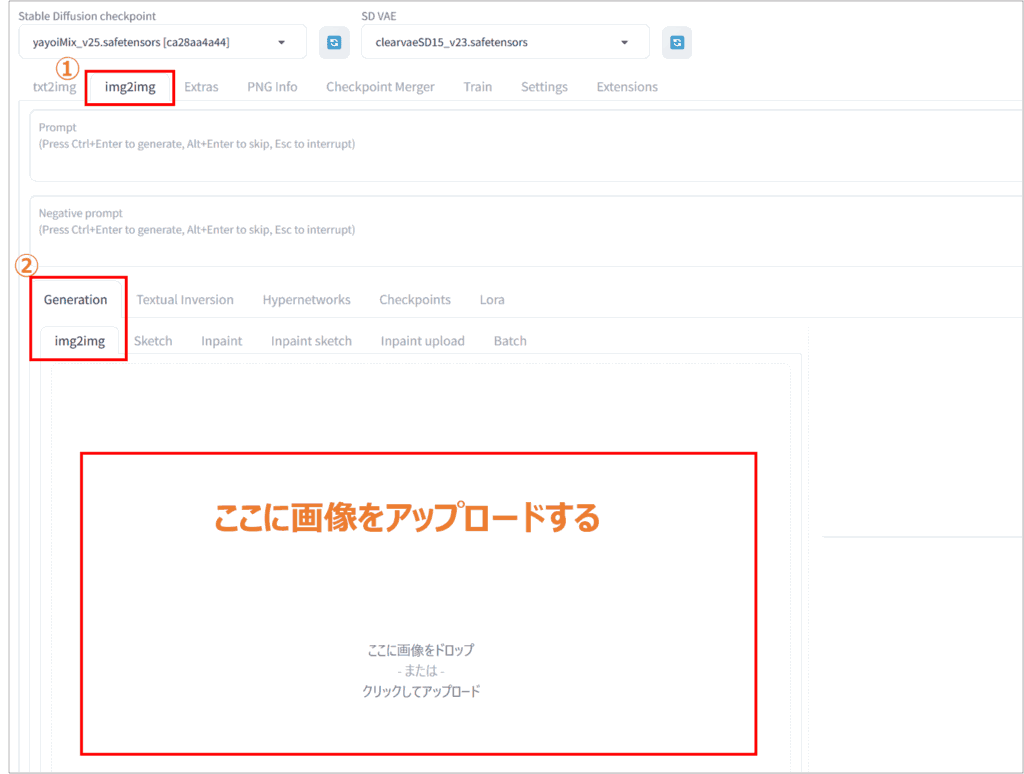
読み込みに成功すると、プレビュー画面に元画像が表示されます。
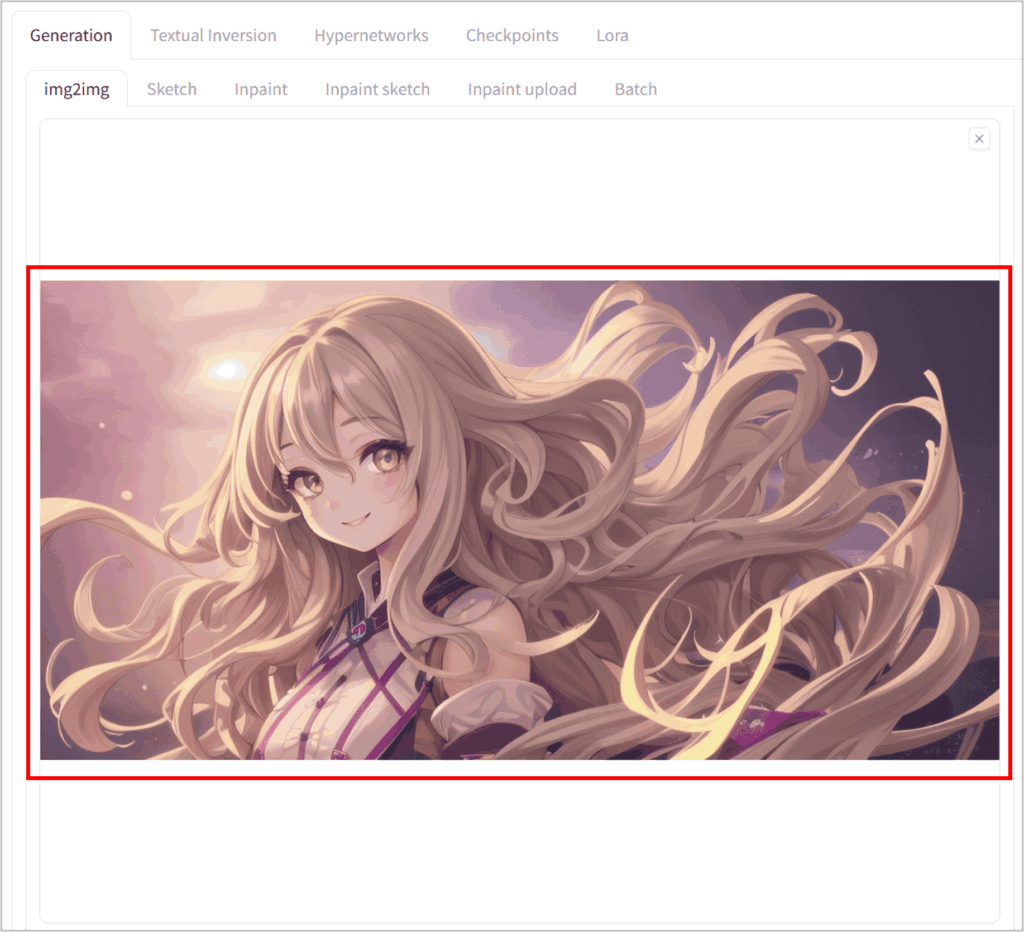
メモリ不足でエラーが起きた場合は、画像サイズを下げるか、生成サイズを抑えるといった対応で解決できることが多いです。もし読み込みがうまくいかない場合は、WebUIのIssuesページを検索して同様の事例をチェックしましょう。
手順3:生成サイズや解像度を指定する
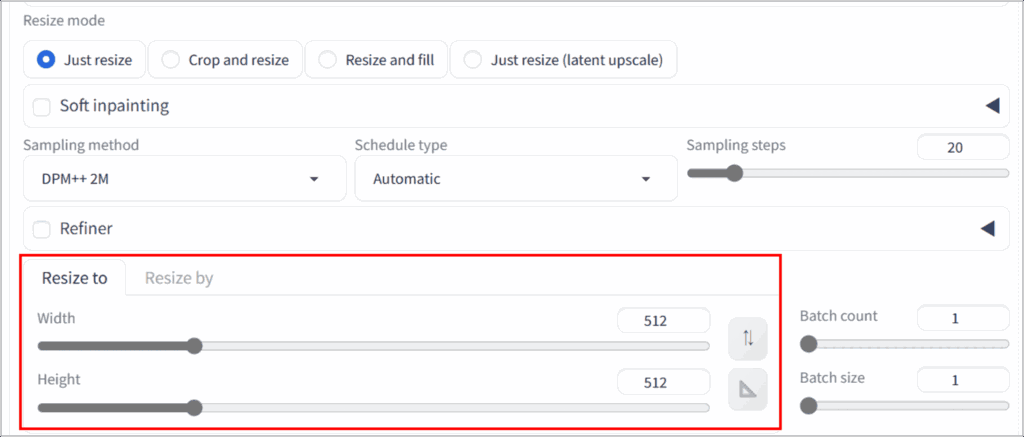
続いて、生成後の画像サイズや解像度を指定します。
Resize toにて、幅(width)と高さ(Height)をピクセル単位で入力し、必要に応じてアスペクト比を変更してください。画像をアップロードした直後は512×512になっています。
今回の手順では、元画像のサイズに合わせることにします。◣ボタンを押すと、自動で元画像と同じサイズが設定されます。
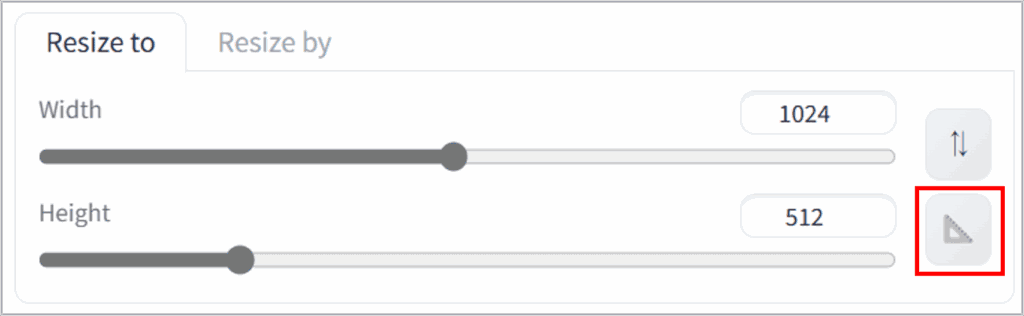
元画像とは別のサイズで新しい画像を生成したい場合は「Resize mode」についても考慮が必要になってきます。「Resize mode」については後述します。
大きいサイズを選ぶほど高いクオリティを期待できますが、その分GPUの負荷も増大します。いきなり大きいサイズは指定せず、700~1000くらいで出力してみて、メモリに余裕があれば徐々に拡大するのがおすすめです。
手順4:プロンプトを入力して画像を生成する
最後に、プロンプトを入力して画像を生成します。
元画像はアニメ風のイラストでしたが、これを実写風に変更します。モデルは「yayoi_mix」を使用します。
プロンプトに「young japanese woman, smiling, long hair, bright eyes, highly detailed, 4K resolution」と入力して、「Generate」ボタンをクリックして画像を生成します。
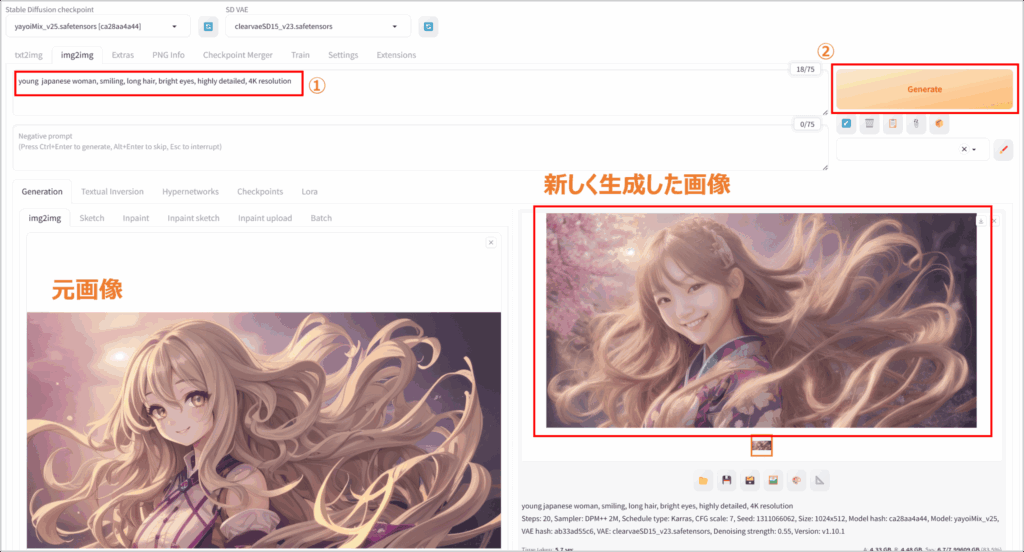
生成結果を確認したら、必要に応じてプロンプトやパラメータを修正して再度生成します。
具体的には、色味が足りないなら「vibrant colors」などのキーワードを追加し、ディテールが欲しいなら「highly detailed」「intricate」といった単語を取り入れると効果があります。
以上のように、モデルやプロンプト、パラメータなどの調整を何度か繰り返すことで理想的な仕上がりに近づけていきましょう。
Stable Diffusion WebUIでimg2imgを使うコツ

Stable Diffusion WebUIでimg2imgを使うコツは以下の通りです。
- ノイズ除去強度(Denoising strength)を指定する
- Inpaintを用いて部分的な修正を行う
- Outpaintingを用いて画像を拡張する
一つずつ見ていきます。
ノイズ除去強度(Denoising strength)を指定する
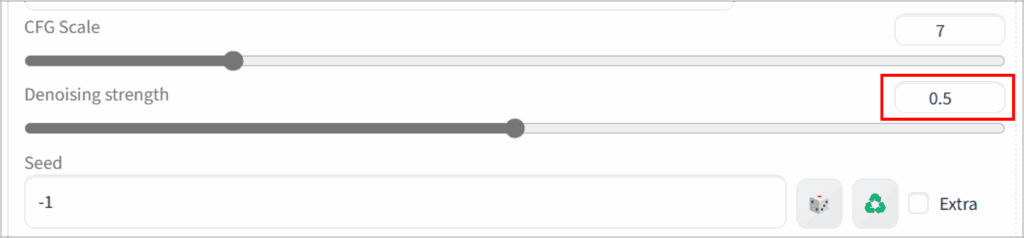
Denoising strengthは、元画像の情報をどの程度残すかを指定するパラメータです。
数値を高めに設定すると大きく変化しますが、元の要素が失われやすくなります。逆に低めにすると変化幅は小さく、ベースの構図を強く残せます。
値が小さいほど元の画像に近い画像を生成できます。
たとえば特徴的なキャラクターの形を維持したいなら値を低めに、背景を大幅に変更したいなら値を高めに設定するのが一般的です。
適切な値はケースバイケースで異なりますが、0.4~0.6前後を目安に微調整していくのがおすすめです。
Inpaintを用いて部分的な修正を行う
Inpaintは、画像の一部を指定してその範囲だけを新たに生成・修正する機能です。
たとえば人の顔だけ描き直したい場合や、背景の不要なオブジェクトを塗りつぶして自然な風景に仕上げたい場合に役立ちます。
WebUIの「Inpaint」タブを選択し画像をアップロードします。マスクを描くように修正部分を指定して「Generate」ボタンをクリック。これにより元画像の他の部分は保持しつつ、指定領域のみ再生成されます。
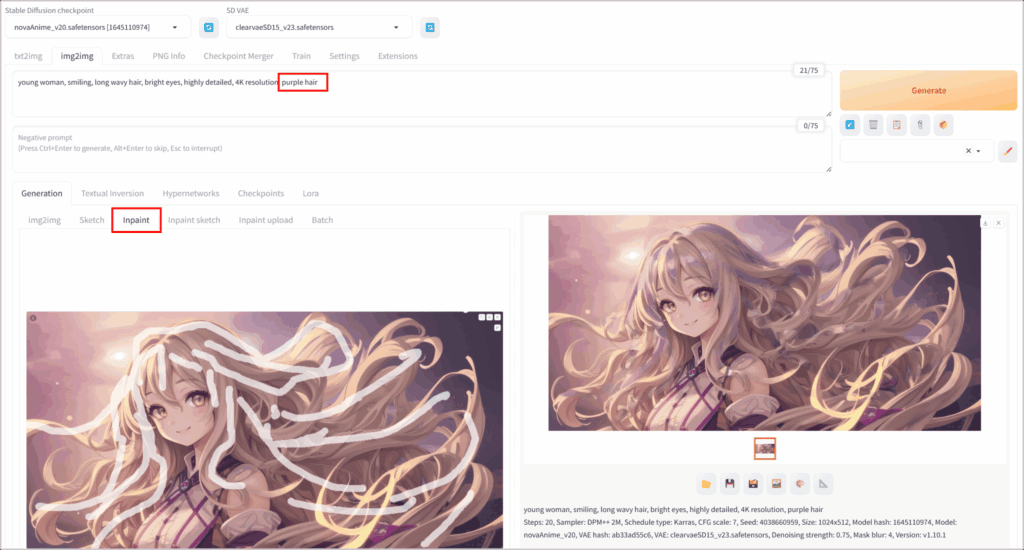
少し分かりにくいですが、髪の一部分を紫色にするように再生成しました。
InpaintはAIによる自動補完のため、イメージ通りの結果が得られない場合もありますが、パラメータを変えたりプロンプトを工夫すれば完成度を高めることが可能です。細部だけ整えたいときに便利です。
Outpaintingを用いて画像を拡張する
Outpaintingは、既存の画像の外側に新たな要素を生成してを背景・構図を拡張する機能です。
たとえば風景写真に余白を足して広大な景色を作ったり、イラストの背景をさらに広げて壮大な構図に仕上げたりできます。
WebUIの「Script」を「Outpainting mk2」を選択し、追加したい部分を指定して生成ボタンを押せば適用されます。あまりに広範囲を一度に拡張すると不自然な繋がりになる場合があるため、部分的に複数回試行するのがポイントです。
Resize modeより生成サイズを変更する
Resize modeとは、元画像とは別のサイズ「幅(width)と高さ(Height)」で新しい画像を生成したい場合、どのように補正・拡大縮小を行うかを指定する機能です。
Resize modeは以下の4つのモードより選択できます。
- Just resize:元画像の縦横比を無視して、指定したサイズに引き伸ばす
- Crop and resize:元画像の縦横比を保ち、指定したサイズに合わせて切り取る
- Resize and fill:元画像の縦横比を保ち、指定したサイズに合わせて余白を埋める
- Just resize(latent upscaler):Just resize+解像度を上げる
まとめ:Stable Diffusion img2imgの使い方を解説
「Stable Diffusion img2imgの使い方」について解説しました。
img2imgとは、既存の画像を元に新たな画像を生成する機能です。img2imgを利用することで、生成したい画像のイメージを伝えやすくなります。
テキストプロンプトのみで生成したい画像のイメージを伝えるのは難しい…という場合にぜひ利用してみてください。
モデルやプロンプト、パラメータなどの調整を何度か繰り返して、イメージ通りの画像に近づけていきましょう!
手順を振り返りたい方は以下のリンクより飛べます。
※リンクをクリックすると解説場所まで飛べます。
コメント