

・Stable Diffusionのモデルの導入手順が知りたい
・モデルを入れる時の注意点が知りたい
という方に向けた記事になります。
Stable Diffusionのモデルとは、テキスト情報から画像を生成するために事前学習されたデータファイルを指します。学習済のモデルをインストールすることで、よりイメージに近い画像生成が可能になります。
Stable Diffusion WebUIをローカル環境に導入した段階では、モデルは基本的なものしか入っていないため、自分でモデルをインストールする必要があります。
そこで本記事では、「Stable Diffusion WebUIのモデルの導入方法」について詳しく解説します。
モデルの選び方からインストール手順、PCの容量やVRAM容量など、モデル導入時の注意点についても解説します。
PCに詳しくない方でもスムーズに導入できるよう、画像付きで分かりやすく解説するので、ぜひ参考にしてください!
Stable Diffusionのモデルとは?

Stable Diffusionのモデルとは、テキスト情報から画像を生成するために事前学習されたデータファイルを指します。
画像生成の元となる重みや数値パラメータが含まれており、ユーザーはこのモデルを読み込むだけで多彩なビジュアルを生み出せます。
モデルによって得意とするタッチや作風が異なるため、目的に応じたものを選ぶことが大切です。
モデルを追加・変更することで、作風を簡単に変えたり、様々なバリエーションの画像を生成することが可能になります。
加えて、モデルを活用するにはグラフィックス処理能力を備えたPCが必要となり、余裕のあるGPUメモリがあるほど大きなサイズや複雑な構図を扱いやすくなります。
初めて利用する場合は、公式ドキュメントやAI関連コミュニティで配布されているモデルを選ぶのがおすすめです。
CheckpointとLoRAの違い
Checkpointとは、学習済みの重みデータ全体をまとめたファイルであり、Stable Diffusionの生成能力をフルに活用するための基盤といえます。
これに対してLoRAは、もともとのCheckpointに対して少量の追加学習データを上乗せする形式です。LoRAを使うと、オリジナルのモデルを大幅に修正せずに特定のテーマやスタイルを強化できます。
例えば、人物イラストの衣装デザインを集中して学習したLoRAを加えると、衣装表現に特化した画像生成が可能になります。
- Checkpoint:モデルの本体。ファイル容量が大きいが、様々な描画スタイルの画像を生成
- LoRA:モデルの追加学習データ。ファイル容量は小さく、特定のスタイルを補強して画像を生成
Checkpointの方がファイル容量は大きく、読み込み時間もかかりますが、多様な描画スタイルをカバーできます。LoRAはファイル容量が小さめで特定のジャンルを補強する性質があり、必要に応じて複数のファイルを簡単に切り替えることが可能です。
本記事ではモデル(=Checkpoint)の入れ方について見ていきます!
モデルのバージョン・容量について
Stable Diffusionのモデルは、バージョンによって画風や生成精度が変わります。最新のバージョンほどノイズ抑制や細部の描写が改善されていますが、環境やGPUメモリを圧迫しやすい点に注意が必要です。
特にファイル容量が大きいモデルでは、起動時にRAMやVRAMの大半を消費する場合があり、スペック不足によるエラーが起こりやすくなります。
初めての方は比較的容量の小さなモデルを試すか、VRAMを8GB以上確保したGPUを利用すると安心です。
| モデルのバージョン | 特徴 | 推奨解像度 | 評価 |
|---|---|---|---|
| SD1.5 | 軽量(2G程度) 生成速度が速い 古い・解像度がSDXLに劣る | 512×512 | 初心者におすすめ |
| SDXL | SD1.5より高解像度 品質の高い画像を生成できる 要求されるVRAM容量が大きい | 1024×1024 | 中級者におすすめ |
Stable Diffusionでは「SD1.5」または「SDXL」が広く利用されています。画像の品質にそこまでこだわらない 、またはPCのスペックが不安な方は「SD1.5」の利用がおすすめ。
できるだけ高品質が良い、またはPCのスペックが十分の方は「SDXL」の利用がおすすめです。
モデルファイルの入手先とダウンロード方法

Stable Diffusionのモデルファイルは、主にオンラインリポジトリやAI関連のコミュニティサイトより無料で入手できます。
- Hugging Faceの公式リポジトリから入手
- Civitaiなどのコミュニティサイト
ダウンロード方法は一般的にZIPファイルや直接のファイルリンクからの取得が多いです。一つずつ見ていきましょう。
Hugging Faceからダウンロード
Hugging Faceは、多くのAIモデルが公開・共有されるプラットフォームとして知られています。
Stable Diffusionにおいても様々なCheckpointやLoRAがアップロードされており、検索機能を利用して目的のモデルを見つけることができます。
ダウンロードする際は、モデルの説明文にあるバージョンや動作実績をよく読み、環境と合っているかを確認する必要があります。
特に、商用利用をしたい方は、利用条件やライセンスについても事前に確認しておきましょう。
ダウンロード手順は、まずHugging Faceにアクセスし、モデルのページへ移動します。
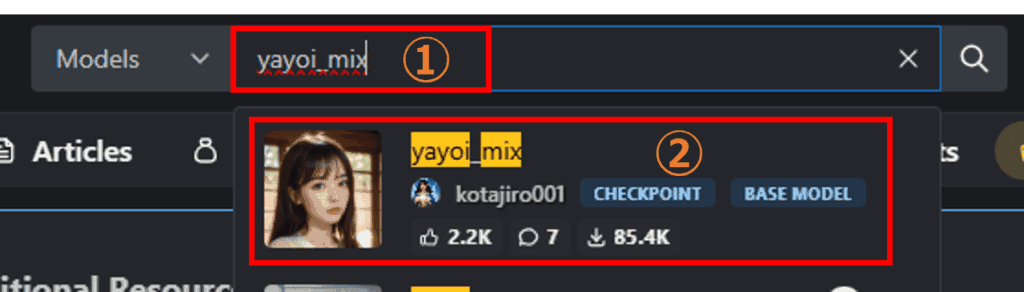
検索窓に「yayoi_mix」と入力して、Kotajiro/yayoi_mixを選択します。
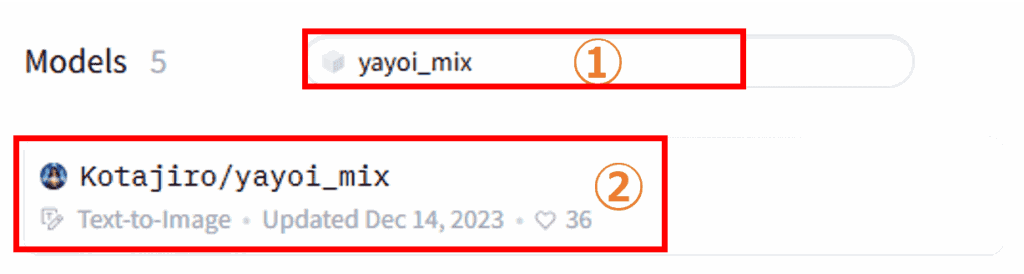
yayoi_mixを利用すると、リアルな日本人女性(美女)の画像を生成できるようになります。お試しで入力してみましたが、検索は何でも大丈夫です。
「Files and versions」タブへ移動して、お好きなバージョンをダウンロードします。
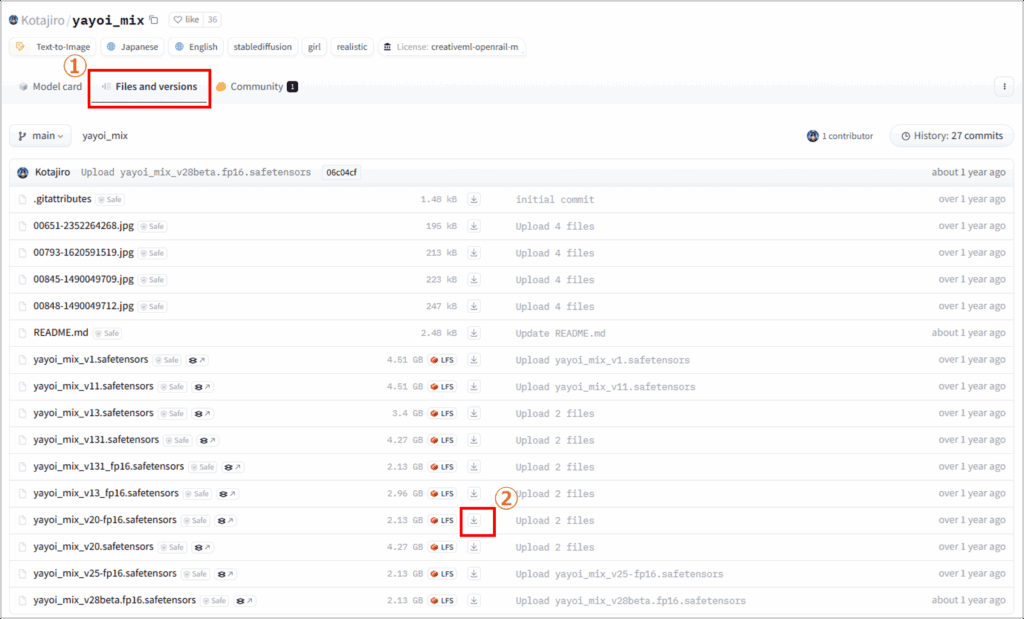
モデルファイルの種類は「fp16版」が、拡張子は「.safetensors」がおすすめです。
fp16版だと、2GBの容量で軽量です。こだわりがない方はfp16版をダウンロードしましょう。
以上でHugging Faceから、モデルのダウンロードは完了です。
Civitaiからダウンロード
Civitaiは、Stable Diffusion関連のモデルを検索しやすいサイトとして人気を集めています。
ユーザーが投稿したCheckpointやLoRA、各種テスト画像などが配布されており、作者が提示する使用例や推奨パラメータを参考にできる点が魅力です。
ページにはモデルのプレビュー画像や動作報告が寄せられ、ダウンロード前に完成イメージを把握しやすい仕組みになっています。
Hugging Faceと同様に、モデルの説明文やリリースノート・利用者の感想などをチェックしてからダウンロードするようにしましょう。
特に、商用利用をしたい方は、利用条件やライセンスについても事前に確認しておきましょう。
ダウンロード手順は、まずCivitaiにアクセスし、モデルのページへ移動します。
モデルページでFilterをかけて好みのモデルを選んでもOKです。今回は検索窓に「yayoi_mix」と入力して、kotajiro001さんのyayoi_mixを選択します。
「Download」ボタンをクリックして、モデルをダウンロードします。
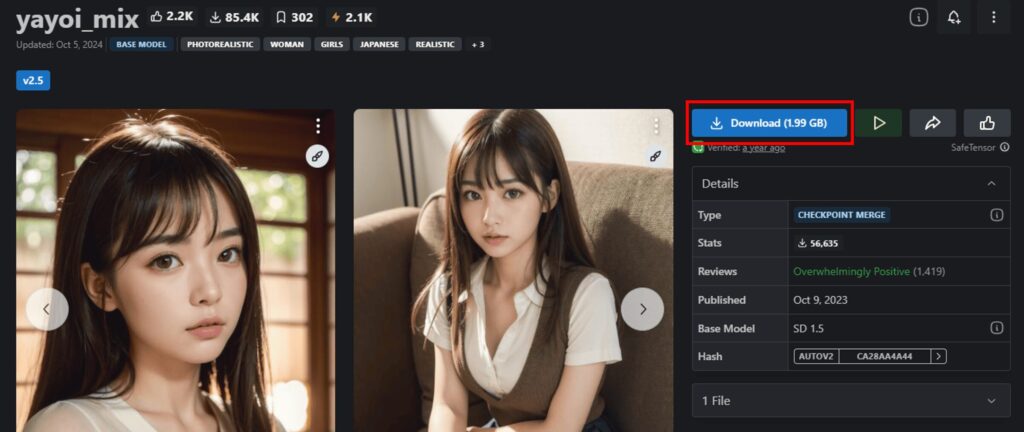
今回はバージョンがv2.5のみだったので迷いませんでしたが、選べる場合は利用者の感想などを参考にして選びましょう。また、ファイルサイズより、ダウンロード先の容量が足りることも確認しておくと良いです。
モデルファイルの種類は「fp16版」、拡張子は「.safetensors」がおすすめです。
以上でCivitaiから、モデルのダウンロードは完了です。
Stable Diffusion WebUIにモデルを導入する手順

Stable Diffusion WebUIにモデルを導入する手順は以下の通りです。
- モデルを選ぶ
- モデルの利用規約や使用条件を確認する
- モデルをダウンロードする
- モデルをインストールする
- モデルを使って画像を生成する
一つずつ見ていきます。
手順1:モデルを選ぶ
まず、Stable Diffusion WebUIで使うモデルを選びます。
モデルは「リアル系写真、アニメ調、背景画やキャラクター特化」などがあり、それぞれが得意とする描写が異なります。
選ぶ際には、必要な表現とモデルの特性が合っているかをチェックし、ファイルサイズや対応バージョンも確認しておきましょう。
どれを選んだらいいか分からない場合は、CivitaiやHugging Faceのランキング上位など人気のモデルから導入してみるのもアリです。
PCスペックとも相談し、無理のない範囲で扱えるモデルを選びましょう。今回の手順では「MeinaMix」というモデルを導入していきます。
手順2:モデルの利用規約や使用条件を確認する
続いて、モデルの利用規約や使用条件を確認します。
モデルには独自の利用規約やライセンスが設定されている場合があり、商用利用や改変、二次配布などに制限がかかっている事例があります。
事前に規約を把握せずに使用すると、後になって法的トラブルに発展する可能性もあります。そのため、モデル提供者の説明文や公式ライセンス表記をよく読み、適切に使用することが大切です。
特にイラストやキャラクターの二次創作に関しては、権利者が厳しく監視している例もあるため注意が必要です。
今回の手順ではCivitaiより「MeinaMix」というモデルを導入しますので、Civitaiにアクセスして、検索窓よりモデル名を検索していきます。

作者が「Meina」さんになっているものを選択します。
ダウンロード予定のバージョンを確認します。「Meina V11」をダウンロードするので選択しておきましょう。
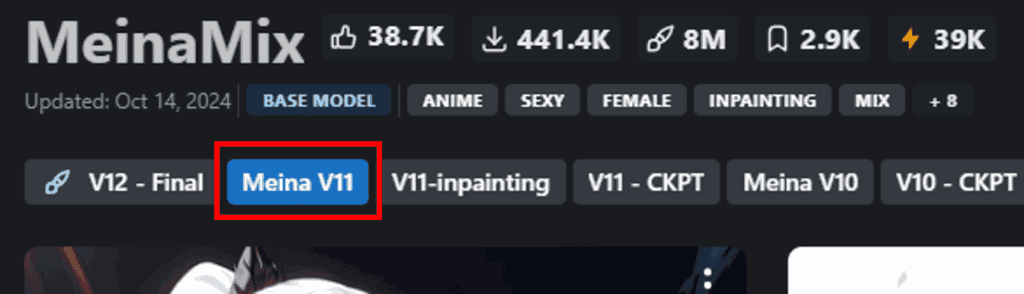
画面右側の作者の欄の下に利用規約・ライセンスの記載があります。
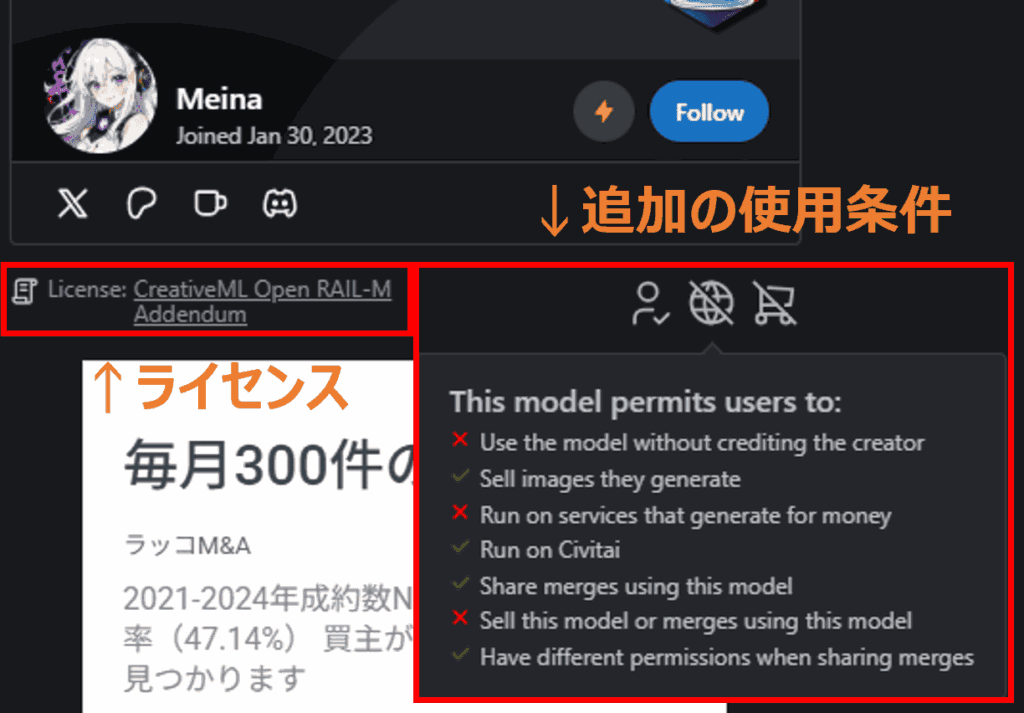
「CreativeML Open RAIL-M」というライセンスはStable Diffusionのライセンスであり、商用利用が可能である認識で問題ありません。
ただし、追加の使用条件によって一部の商用利用が制限されるため、こちらをよく確認しておきましょう。
手順3:モデルをダウンロードする
続いて、モデルをダウンロードします。
モデルをダウンロードする際には、ファイルのサイズや拡張子を必ず確認してください。
モデルファイルの容量は数GBを超えるケースもあるため、事前にディスク空き容量が問題ないかを確認すると安心です。
また、拡張子は「.safetensors」または「.ckpt」が用いられますが、セキュリティ面で不正改ざんのリスクを減らせる形式とされている「.safetensors」を選択するのがおすすめです。
ファイルのサイズや拡張子は以下の赤枠内より確認できます。
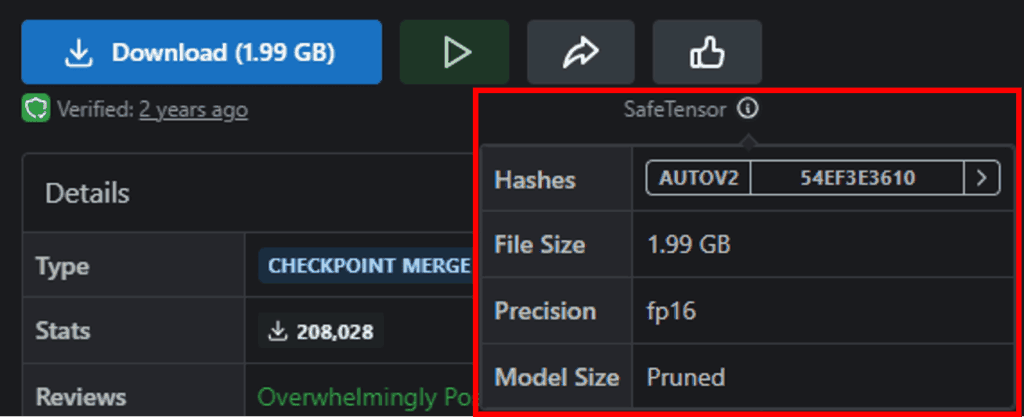
ファイルのサイズや拡張子が確認できたら、「Download」ボタンをクリックしてモデルをダウンロードします。
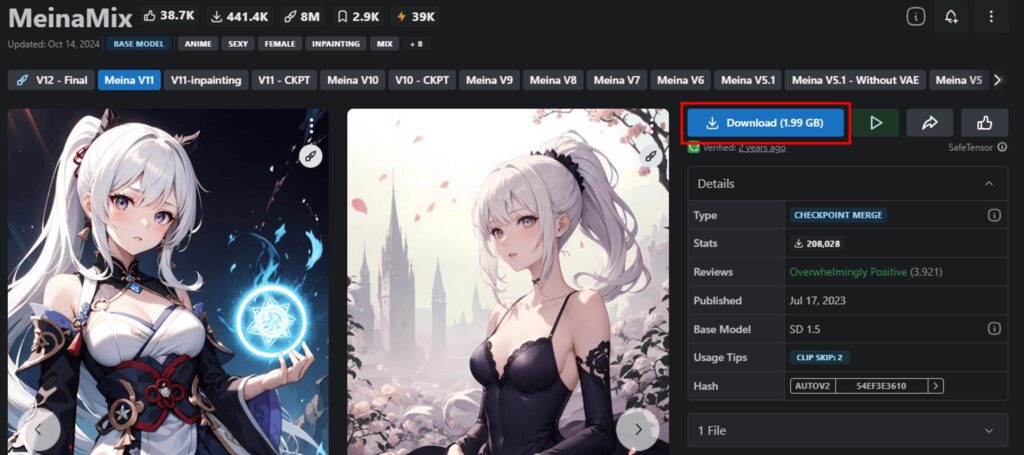
ファイルの大きさにもよりますが、10分程度かかります。気長に待ちましょう。
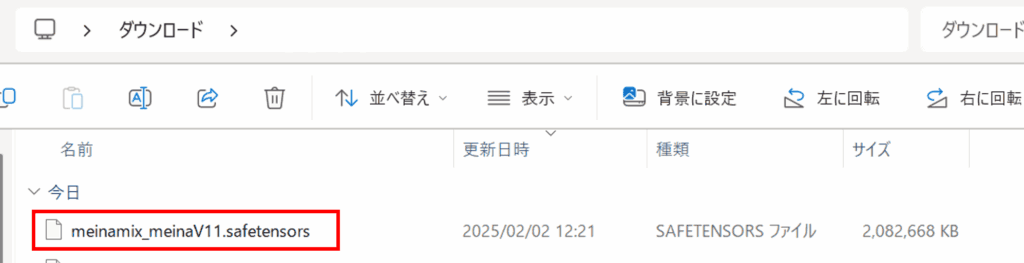
手順4:モデルをインストールする
続いて、モデルをインストールします。
「C:\StableDiffusion\stable-diffusion-webui\models\Stable-diffusion」にダウンロードしたモデルファイルを配置します。

Stable Diffusion WebUIを起動して、モデルデータが選択できるようになっているか確認して、OKです。
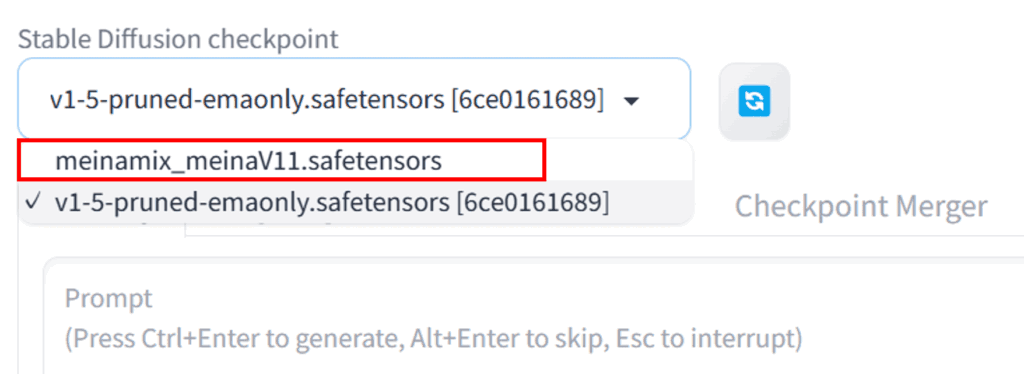
もしWebUIを起動・再起動してもファイルが認識されないときは、パス設定が誤っているかもしれないので、確認してみてください。
手順5:モデルを使って画像を生成する
最後に、モデルを使って画像を生成します。
Stable Diffusion WebUIで選択リストから追加したモデルを指定できるようになりました。あとはテキスト入力欄や設定パネルからパラメータを入力するだけで、絵柄を反映した画像が自動生成されます。
モデル「MeinaMix」を選択して、プロンプト「beautiful girl, big eyes, long hair, dynamic pose, vibrant colors, soft lighting, upper body shot」を入力して生成ボタンをクリックしてみました。
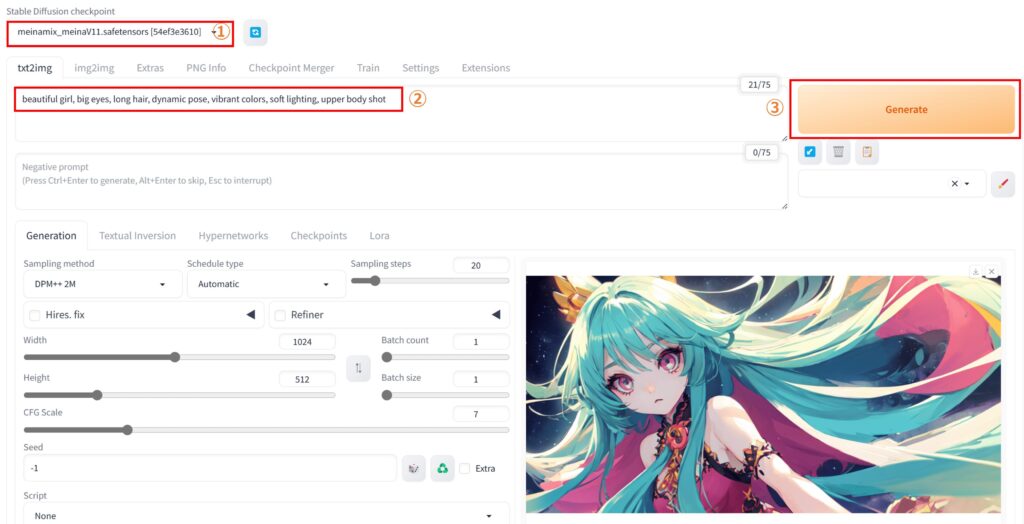
作風がガラッと変わったのが実感できました。以上のように、モデルの追加・変更は簡単に行えるため、色々なモデルを試してみて、自分好みの画像を生成していきましょう。
Stable Diffusion WebUIでモデルを利用する時の注意点

Stable Diffusion WebUIでモデルを利用する時は、以下の注意点について気を付けておくと、安心して利用できます。
商用利用や著作権について確認する
Stable Diffusionで作成した画像を商用利用する際は、使用したモデルのライセンスをよく確認してください。
モデルの作者が商用利用を禁じている事例や、改変を制限する条件を設けている場合があります。著名なキャラクターや既存イラストを再学習させたモデルでは、権利問題が起こりやすいため注意が必要です。
特に収益化を考えている方は、権利表記や引用元の明記などを徹底し、安全に利用するように努めましょう。
モデルがリストに表示されない場合はリフレッシュする
Stable Diffusion WebUIにモデルを配置しても、リストに反映されない場合があります。その場合は、WebUIを再起動するか、リロードを試してみてください。
もしWebUIを再起動・リロードしてもファイルが認識されないときは、パス設定が誤っているかもしれないので、確認してみてください。
モデルの拡張子は「.safetensors」を選ぶ
安定したセキュリティのため、「.safetensors」形式のモデルを選ぶことが推奨されています。
「.safetensors」は不正な改ざんのリスクを抑える仕組みを備えた形式で、不審なコード注入やファイル破損の発生率を下げる効果が期待できます。
安全面を重視するなら「.safetensors」形式のモデルを優先的に選びましょう。
まとめ:Stable Diffusion WebUIのモデルの入れ方を解説
「Stable Diffusion WebUIのモデルの導入方法」について解説しました。
Stable Diffusionのモデルとは、テキスト情報から画像を生成するために事前学習されたデータファイルを指します。
Stable Diffusion WebUIをローカル環境に導入した段階では、モデルは基本的なものしか入っていないため、自分でモデルをインストールする必要があります。
モデルを追加することで、よりイメージに近い画像生成が可能になります。ぜひ試してみてください!
手順を振り返りたい方は以下のリンクより飛べます。
コメント